

16 de julho de 2016 • 5 min de leitura
Porque eu evito funções anônimas
Funções anônimas podem esconder uma má prática.
Introdução
Fala pessoal, vamos lá que esse será um post simplão, mas importante para evitar algumas más práticas em nosso código Javascript.
Enquanto escrevo, vou ouvindo uma playlist chamada Infinite Indie Folk, adoro esse estilo de música para relaxar e hoje, um sábado lindo e eu aqui na rede, tinha que ouvir algo assim.
Como criar funções em JS?
Existem diversas formas de se criar funções em JS e algumas delas são:
var hey = function() {
console.log('Hey');
}
function hey() {
console.log('Hey');
}
obj.hey = function() {
console.log('Hey');
}
Se você reparar, a primeira forma estou nomeando a função através de uma variável e a segunda eu estou nomeando da forma tradicional. Mas precisamos tomar cuidado com o funcionamento dessas formas, por quê?
Funções anônimas são difíceis de debugar
Vamos supor que eu tenha uma função que joga um erro qualquer quando executada:
setTimeout(function() {
throw new Error('hey');
}, 200);
Quando executar essa função, o erro claramente é jogado no console, como podemos verificar na imagem abaixo:
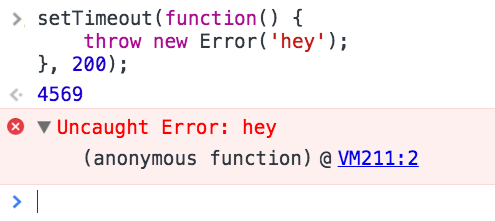
O problema aqui é que apesar dele jogar o erro, eu não sei a fonte do erro, pois o erro está atribuído a uma função anônima.
Agora escrevendo a mesma função, porém nomeada:
setTimeout(function Hey() {
throw new Error('hey');
}, 200);
Olha como fica o retorno:
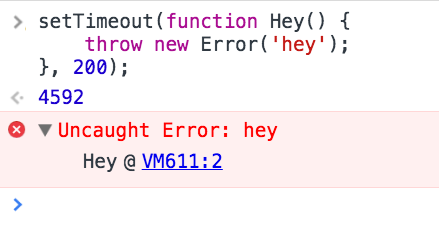
Quando abrimos o erro, podemos ver claramente que o erro se encontra na função Hey e isso já facilitaria nossa debugagem.
Funções anônimas não são reutilizáveis
Digamos que eu queira criar um evento, que ao clicar num certo elemento, ele adicione/remova uma classe. Em Javascript puro eu poderia fazer algo como:
document.querySelector('.item').addEventListener('click', function(event) {
this.classList.toggle('active');
});
Você pode olhar o método acima e falar: Mas o que tem de errado aí? De fato, não tem nada de errado, mas se eu quisesse utilizar o mesmo método para outro seletor? Não daria né. Por que não fazer assim então:
function toggleActive() {
this.classList.toggle('active')
}
document.querySelector('.item').addEventListener('click', toggleActive)
document.querySelector('.another-item').addEventListener('click', toggleActive)
Funções declaradas facilitam o desacoplamento
Vamos pensar num código simples de node, onde apendamos um texto e notificamos o usuário, vamos primeiro ver um exemplo comum que pessoas fazem, usando funções anônimas:
var fs = require('fs');
var myFile = '/tmp/test';
fs.readFile(myFile, 'utf8', function(err, txt) {
if (err) return console.log(err);
txt = txt + 'Mais algum texto!';
fs.writeFile(myFile, txt, function(err) {
if(err) return console.log(err);
console.log('Texto adicionado!');
});
});
Ali temos um arquivo de texto myFile que é lido e adicionado Mais algum texto!, então escrevemos no arquivo e informamos o usuário da tarefa concluída.
Se repararmos, temos ali duas funções anônimas, que por si só, já poderiam acusar erro e nem saberíamos corretamente de onde vem. Outra coisa é que temos um início de um callback hell de função chamando função que é horrível!
Para melhorar isso, poderíamos primeiro nomear as funções, para já pelo menos saber de onde o erro vem:
var fs = require('fs');
var myFile = '/tmp/test';
fs.readFile(myFile, 'utf8', function appendText(err, txt) {
if (err) return console.log(err);
txt = txt + 'Mais algum texto!';
fs.writeFile(myFile, txt, function notifyUser(err) {
if(err) return console.log(err);
console.log('Texto adicionado!');
});
});
Tendo os nomes, caso algum erro dos erros estoure na tela, já saberemos de onde vem. Mesmo assim, ainda está bem ruim de ler e ficou ainda mais sujo colocando os nomes, então por que não separar as funções?
var fs = require('fs');
function notifyUser(err) {
if(err) return console.log(err);
console.log('Texto adicionado!');
};
function appendText(err, txt) {
if (err) return console.log(err);
txt = txt + 'Mais algum texto!';
fs.writeFile(myFile, txt, notifyUser);
}
var myFile = '/tmp/test';
fs.readFile(myFile, 'utf8', appendText);
Olha como ficou mais fácil, temos as nossas funções separadas com suas responsabilidades ÚNICAS e o código ficou muito mais fácil de ler e entender.
Outras coisinhas mais...
As funções anônimas são difíceis de testar, pois como ela não são chamadas diretamente, eu preciso chamar um método terceiro para averiguar o funcionamento da mesma e isso é um baita de um code smell (código perigoso/errado).
Funções anônimas não descrevem o funcionamento/responsabilidade única das mesmas, então será necessário que todo o código seja lido, para de fato entender para que serve, imagina se forem milhares de funções assim?
Programas que criam documentação automática como o jsDoc irão ter grandes problemas com esses tipos de métodos e as vezes irão até deixar de marcar/documentar, o que é ruim quando se precisa de um código altamente documentado, como API's, por exemplo.
Conclusão
Bom galera, como disse lá na parte de cima, não estou dizendo para nunca usar função anônima, muito pelo contrário, em vários momentos elas de fato podem ser úteis, principalmente se unidas a filter, map, reduce e arrow functions. Mas o importante é prestar atenção em seu código, existem momentos em que declarar funções vai te evitar grandes dores de cabeça.